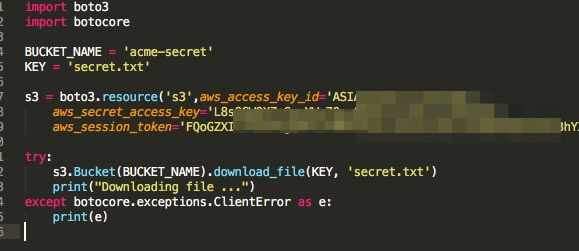
Amazon came up with many innovative and interesting announcements about new technologies and services provided by them during the recent AWS "re:Invent" event. One of the widely discussed topic in the event was "serverless". With the increasing usage of AWS lambda, it is imperative to understand anything that impacts the lambda architecture in any way. The below two announcements were quite important for security professionals as they directly deal with serverless changes and its implications.
Firecracker - Firecracker is Amazon’s micro VM, which runs lambda functions, and it will be open source. Hence, anybody can play around and understand it's working. For more details: - https://aws.amazon.com/blogs/aws/firecracker-lightweight-virtualization-for-serverless-computing/
Lambda Layers and Runtime APIs - Lambda functions allow a holding place in terms of layers. One can deploy set of layers and can execute these layers with Runtime APIs or leverage packages deployed in these layers. For more details: - https://aws.amazon.com/about-aws/whats-new/2018/11/aws-lambda-now-supports-custom-runtimes-and-layers/
In this post, we are going to explore Layers and Runtime APIs.
AWS was supporting a set of runtime environment predefined within lambda functions. With the introduction of Layers and Runtime APIs, that it no longer a limitation. It now supports and allows to load one's own runtime binaries and leverage it across the lambda eco-system. Thus, now support has been added for Ruby, C++, and Rust etc. making it a Bring Your Own Runtime kind of scenario.
Their tutorial (https://docs.aws.amazon.com/lambda/latest/dg/runtimes-walkthrough.html) explains how to configure and invoke one's own runtime through layering and APIs. We are going to modify the scripts mentioned in this tutorial and deploy our runtime through the management console for better understanding.
First, we need to make our own bootstrap to start the activity of lambda functions within shell. This is the shell script which one can run and initiate any environment and binaries within it. It supports runtime APIs so one can fetch the "event" and pass it to lambda handler.
Here is the sample bootstrap script: -
--bootstrap—
#!/bin/sh
set -euo pipefail
# Initialization - load function handler
echo $_HANDLER >> /tmp/dump
env >> /tmp/dump
source $LAMBDA_TASK_ROOT/"$(echo $_HANDLER | cut -d. -f1).sh"
# Processing
while true
do
HEADERS="$(mktemp)"
# Get an event
EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next")
cat $HEADERS >> /tmp/dump
echo $EVENT_DATA >> /tmp/dump
REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2)
echo $REQUEST_ID >> /tmp/dump
# Execute the handler function from the script
RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA")
# Send the response
curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE"
done
Let’s look at few important lines: -
1. We are using /tmp/dump to put interesting values to it so we can read them through the function and pass it back as response as well.
2. "EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next")" – this line will fetch "event" through runtime from underlying localhost (127.0.0.1).
3. "RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA")" – once we have "event" with us we can invoke our own local function and fetch the response. It is like calling another script or you can pass it to any other runtime binaries.
4. Finally, "curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" – we send response back to the client through runtime API.
We just have to make sure these files are "chmod 755" as shown below: -
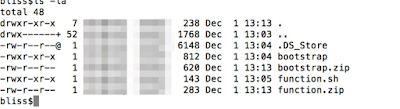
We can zip the file to "bootstrap.zip" and create a new layer for lambda.
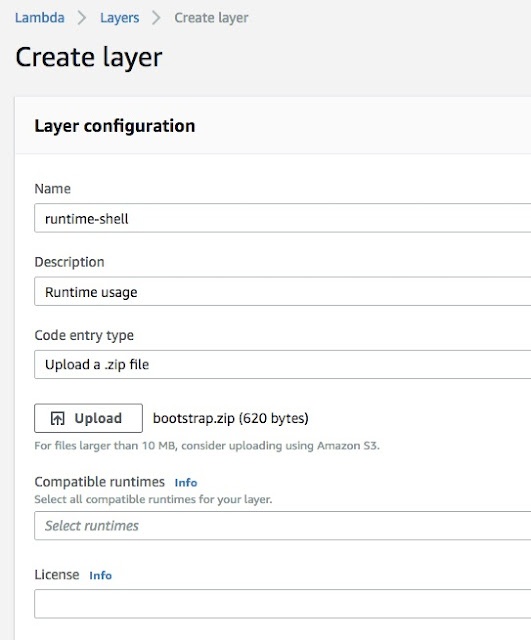
We can upload the zip file and create a runtime layer as below: -
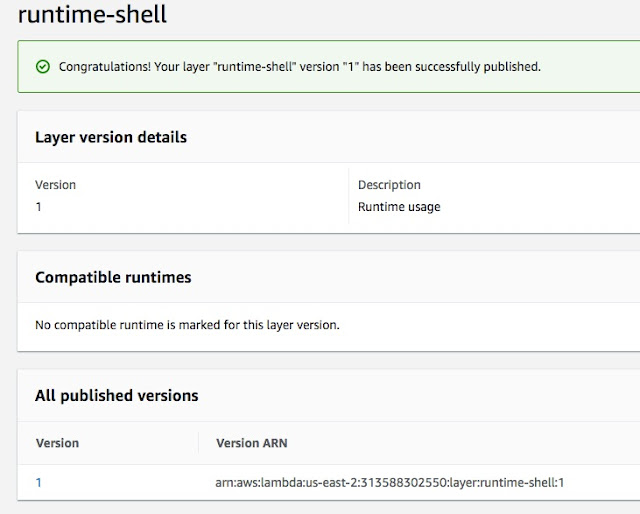
Now, we have runtime-shell layer read. We can utilize this layer/runtime and build many lambda functions using simple shell scripts. Let’s make a function here called "runlambda": -
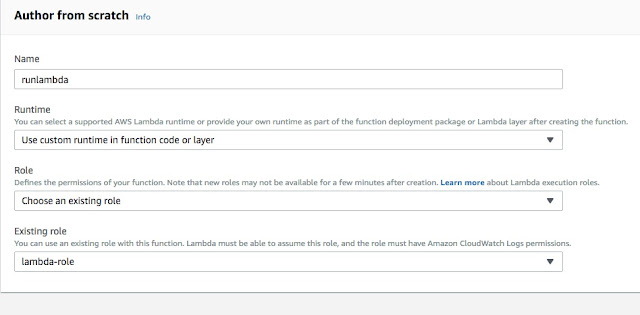
We select "custom runtime" as our environment. Next, let’s load the layer which we want to use: -
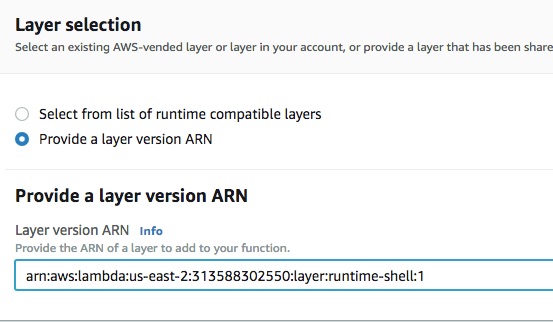
As shown in the above screenshot, we pass on ARN to the layer and then it is ready: -
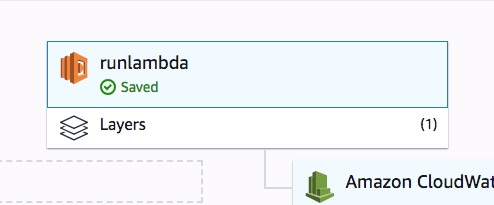
Next, let’s load simple echo function as below (function.sh). We are doing simple cat to the entire dump we collected in the bootstrap along with the event.
--function.sh--
function handler () {
EVENT_DATA=$1
echo "$EVENT_DATA" 1>&2;
cat /tmp/dump
RESPONSE="Echoing request: '$EVENT_DATA'"
echo $RESPONSE
}
Next, we can load this function as zip to the lambda function as shown below: -
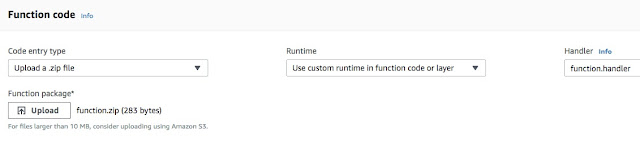
All set! We can invoke the function as below: -
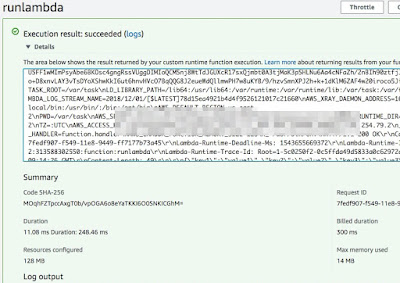
We can also invoke the function through our script (scanLambda.py) as below: -
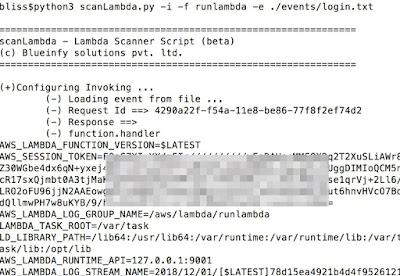
We are getting a dump of all the variables available in the bootstrap layer: -
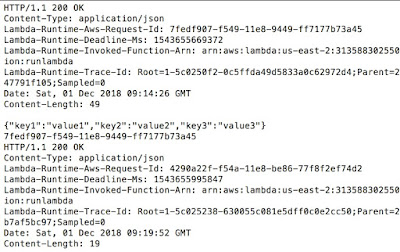
Above, we have cURL calls made to APIs.
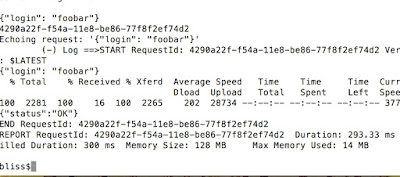
Finally, we have echo coming back from the function itself.
Article by Amish Shah & Shreeraj Shah
Firecracker - Firecracker is Amazon’s micro VM, which runs lambda functions, and it will be open source. Hence, anybody can play around and understand it's working. For more details: - https://aws.amazon.com/blogs/aws/firecracker-lightweight-virtualization-for-serverless-computing/
Lambda Layers and Runtime APIs - Lambda functions allow a holding place in terms of layers. One can deploy set of layers and can execute these layers with Runtime APIs or leverage packages deployed in these layers. For more details: - https://aws.amazon.com/about-aws/whats-new/2018/11/aws-lambda-now-supports-custom-runtimes-and-layers/
In this post, we are going to explore Layers and Runtime APIs.
AWS was supporting a set of runtime environment predefined within lambda functions. With the introduction of Layers and Runtime APIs, that it no longer a limitation. It now supports and allows to load one's own runtime binaries and leverage it across the lambda eco-system. Thus, now support has been added for Ruby, C++, and Rust etc. making it a Bring Your Own Runtime kind of scenario.
Their tutorial (https://docs.aws.amazon.com/lambda/latest/dg/runtimes-walkthrough.html) explains how to configure and invoke one's own runtime through layering and APIs. We are going to modify the scripts mentioned in this tutorial and deploy our runtime through the management console for better understanding.
First, we need to make our own bootstrap to start the activity of lambda functions within shell. This is the shell script which one can run and initiate any environment and binaries within it. It supports runtime APIs so one can fetch the "event" and pass it to lambda handler.
Here is the sample bootstrap script: -
--bootstrap—
#!/bin/sh
set -euo pipefail
# Initialization - load function handler
echo $_HANDLER >> /tmp/dump
env >> /tmp/dump
source $LAMBDA_TASK_ROOT/"$(echo $_HANDLER | cut -d. -f1).sh"
# Processing
while true
do
HEADERS="$(mktemp)"
# Get an event
EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next")
cat $HEADERS >> /tmp/dump
echo $EVENT_DATA >> /tmp/dump
REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2)
echo $REQUEST_ID >> /tmp/dump
# Execute the handler function from the script
RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA")
# Send the response
curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE"
done
Let’s look at few important lines: -
1. We are using /tmp/dump to put interesting values to it so we can read them through the function and pass it back as response as well.
2. "EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next")" – this line will fetch "event" through runtime from underlying localhost (127.0.0.1).
3. "RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA")" – once we have "event" with us we can invoke our own local function and fetch the response. It is like calling another script or you can pass it to any other runtime binaries.
4. Finally, "curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" – we send response back to the client through runtime API.
We just have to make sure these files are "chmod 755" as shown below: -

We can zip the file to "bootstrap.zip" and create a new layer for lambda.

We can upload the zip file and create a runtime layer as below: -

Now, we have runtime-shell layer read. We can utilize this layer/runtime and build many lambda functions using simple shell scripts. Let’s make a function here called "runlambda": -

We select "custom runtime" as our environment. Next, let’s load the layer which we want to use: -

As shown in the above screenshot, we pass on ARN to the layer and then it is ready: -

Next, let’s load simple echo function as below (function.sh). We are doing simple cat to the entire dump we collected in the bootstrap along with the event.
--function.sh--
function handler () {
EVENT_DATA=$1
echo "$EVENT_DATA" 1>&2;
cat /tmp/dump
RESPONSE="Echoing request: '$EVENT_DATA'"
echo $RESPONSE
}
Next, we can load this function as zip to the lambda function as shown below: -

All set! We can invoke the function as below: -

We can also invoke the function through our script (scanLambda.py) as below: -

We are getting a dump of all the variables available in the bootstrap layer: -

Above, we have cURL calls made to APIs.

Finally, we have echo coming back from the function itself.
Conclusion:
Lambda Layers and Runtime APIs enable the use of binaries or shell scripts as well as our choice of programming languages. Moreover, one can centrally manage common components across multiple functions enabling better code reuse. This implementation will have its own set of security concerns as well – thus making it necessary to understand the customized layers and runtime APIs before evaluating the function from a security standpoint.Article by Amish Shah & Shreeraj Shah