Implementation
There is surge in document-based GPT implementations for ease of reading, summarizing, translating, extracting key information from large documents which would take up a lot of manual effort in reading. These implementations enhance productivity and accessibility across various fields by leveraging advanced language understanding capabilities. This specific implementation, in a legal organization was an application that allowed end users to upload documents for two specific use cases: -
1. Personal Documents – An end user can upload documents and then retrieve information from the uploaded documents, summarize or translate the documents. This was mainly used for uploading case files where the end user could query for case related information.
2. Shared Documents – An end user can create a persona with a set of documents and then have other users also Q&A from that set of documents. This was mainly used for uploading books related to law so that anyone in the organization could fetch for particular acts/clauses when required.
The implementation (which required a set of personal as well as shared documents within the organization) used a blob storage to store the documents uploaded to the system.

The built in application functionality was a file upload interface for users to upload files and a chat interface to ask questions. The users would directly utilize the chat interface to query from the documents asking for information related to a specific case/acts or clauses specific to some law etc.
Genuine Prompts: -
1. Can you summarize Case 104 for me?
2. Can you provide Clause 66(a) of the Industrial Dispute Act?
3. Who are the key witnesses in Case 103?
Vulnerability
There are two main vulnerabilities that were identified in this implementation: -
1. A lack of authorization/partitioning in the blob storage led to one user accessing, retrieving information from documents uploaded by other users intended for his own use of the application. This was more of a traditional application layer attack caused due to poor permission handling on the server side.
Vulnerable Request (Example)

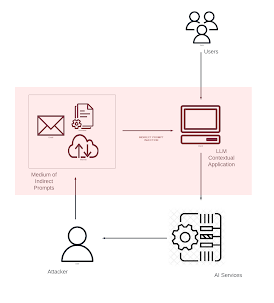
2. A user tends to upload a document (shared documents) with malicious data which feeds instructions (indirect prompt injection) to the LLM to steal sensitive information from the users of the GPT implementation. It kept on prompting the user for his personal details and tries to poke the users to fill surveys after answering the questions due to consumption of instructions from document data. This type of LLM behavior can be maliciously used to cause mass phishing attacks in the organization. Sometimes, an indirect prompt injection can additionally lead to data exfiltration where the indirectly fed prompt can give the LLM system instructions to grab document content/chat history etc. and send it to a third party server (via a HTTP request) through images with markdown.
Vulnerable Document (Example)

Impact
This kind of data leakage completely impacts the data confidentiality of all users using the application and also leads to compliance issues due to leakage/stealing of PII information from the users of the application. Additionally, the sensitivity of the data in the documents/leaked data is a key factor in assessing the impact for this vulnerability.
Fixing the Vulnerability?
The first and foremost fix that was deployed for this vulnerability is an authorization (permission layer) fix at the blob storage level where unintended document access is resolved. Additionally, there were some guardrails implemented which helped prevent the model from producing and even responding to harmful, biased, or incorrect inputs/outputs and ensure compliance based on legal and ethical stand.
Article by Rishita Sarabhai & Hemil Shah